Predicting difficulty in New York Times Crossword puzzles
As part of the Erdős Institue May 2021 Data Science Boot Camp, my group investigated patterns in 27 years worth of New York Times Crossword puzzle data. My group consisted of Caitlin Carpenter and Jonathan Viereck, and the work described here is a shared effort among the three of us.
We extracted a number of features from the raw puzzle data, such as clue length, hint length, density of the puzzle grid, and so one. Our goal was to build a model that can predict what day of the week a puzzle falls on, because (at least for the NY Times) different puzzle difficulties correspond to different days of the week.
One of the highest accuracy models is a classifier based on a tf-idf vectorization of the puzzle data. Using a tf-idf score on the puzzle data means that words unique to certain days of the week should be weighted higher than words common to all puzzles overall, so it’s like to pick up if certain topics or keywords are used in “harder” vs. “easier” puzzles. The confusion matrix for this model is shown below. Each axis is a possible label, and this matrix shows both how accurately each label is predicted, and what other lables a category is incorrectly classified as.
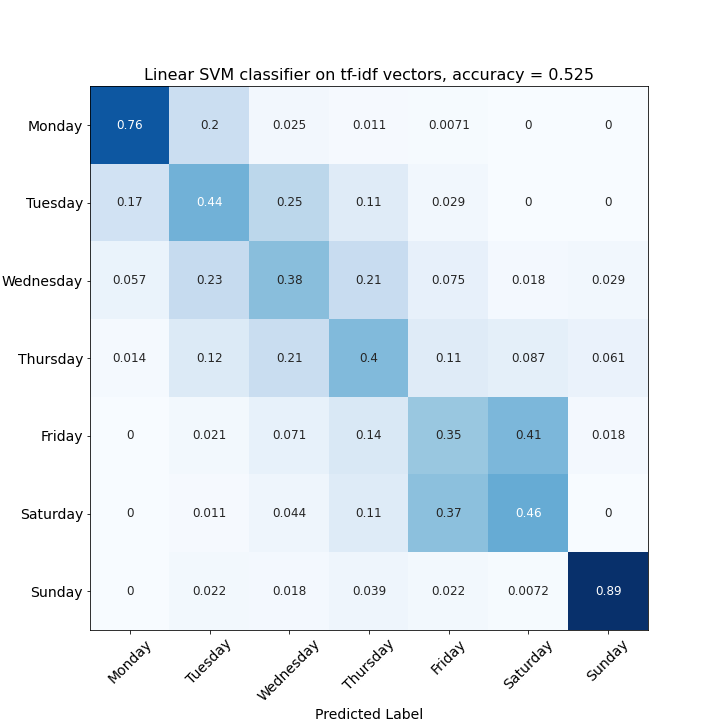
Mondays and Sundays are very easily classified. A perfect classifier would have a solid line of blocks from top-left to bottom-right. This image shows that other days of the week, while less accurately classified, are often confused for adjacent days of the week. This is likely because those puzzles are quite similar to the adjacent days. (For example, Friday and Saturday look to be very similar.) Even though the overall accuracy hovers around 50%, choosing a day simply by chance would give around a 14% accuracy (1 over 7).
The full project is available here.